

ML is a tool for solving a specific class of problems.
Let’s consider the following example to understand the main types of problems that machine learning algorithms solve, and why such issues are unsolvable (or hard to be solved efficiently) using explicit methods.

For example, we need a program that defines a photo of fruit as an apple or a tangerine. (Alternatively, designing a program that has to recognize a malignant tumor on an X-ray image, detect fraud, etc.)
1) The obvious way to solve this task is to get a person (an employee) with good eyesight to label the given photo. Clearly, this approach has its drawbacks:
a) The employee may get tired, sick, or skip work for some other reason
b) The employee needs to get paid, provided with insurance and a replacement during vacation
c) A person (in comparison with a computer) is rather slow in decision making
d) Humans make mistakes
2) Consequently, we decided to write a program that would solve our problem instead of a person. We could even gather the world’s leading experts on tangerines and apples to describe all the possible ways to differentiate these fruits from each other. As a result, we would get a program that, based on the color of the fruit, the length of the leaf and the oblongness of the fruit, tells us whether it is an apple or a tangerine. The system could work fine for a while until we come across an apple with a leaf similar in shape to a tangerine one, or a reddish apple (almost orange) like a tangerine, or a rather round-shaped apple. The human would immediately see that it is an apple, but our program would conclude: “This is a tangerine!” Then we would gather the experts again, investigate the problematic cases, add some rules to the program… The upgrading of the program in this fashion will happen from time to time until we achieve the desired result.
Cons of this approach:
a) High development cost (experts fees, programmers salaries, etc.)
b) The resulting program will be very complex and difficult to maintain.
c) Long development span
d) The inability to discover all necessary dependencies in the problem field at once, and to jointly describe all possible cases and differences
3) Understanding that options 1 and 2 are unsuitable for us, we look for alternative ways to solve this problem and turn to machine learning algorithms. Using suitable ML algorithms, we get a program that, after being trained on a large number of photos of apples and tangerines, can extract the necessary dependencies from the data and solve our problem.
Cons:
a) A large amount of labeled data is required (a large number of photos of apples and tangerines marked accordingly)
Now let’s imagine that we have not 2 but 100 types of fruits: in this case, option 2 (writing our software without using ML) becomes completely infeasible. Even more, much more complicated problems, rather than fruit recognition, are possible, which would in turn be more difficult to implement explicitly. For example, malignant tumor recognition on X-ray images, fraudulent activities with bank cards, spam detection, speech recognition, etc.. Some tasks are just irrational (almost impossible) to solve without the ML tools.
Having figured out why we need ML, let’s see what tasks it is suitable for.
The main tasks that machine learning algorithms solve are issues that are difficult or impossible or not rational to solve in direct, explicit software or in an analytical way. Among these tasks (according to the type of problems), the following 4 can be distinguished:
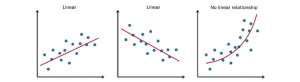
Regression is the problem of predicting a continuous numerical value for a specific object based on its characteristics. For example, the real estate market prices forecast, the temperature forecast, the prediction of the amount of money the client will spend in the store, etc.
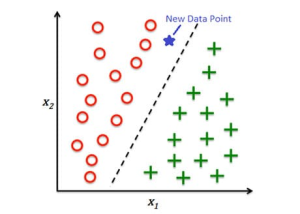
Classification is the task of predicting a categorical attribute of an object. For example, categorization of incoming emails into spam and non-spam, the task of credit scoring, image classification, etc.
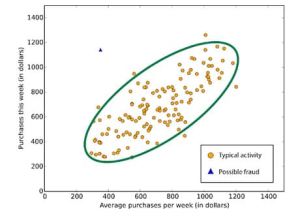
Anomaly detection is the task of identifying items, events or observations that do not match the expected pattern or other items in the dataset. For example fraud detection, system failure detection, discovering mistakes in a text, etc.
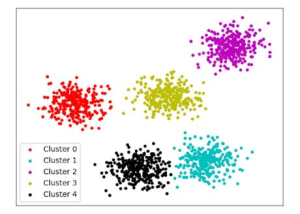
Clustering is the task of grouping similar objects into clusters. Unlike the classification problem, the number of clusters and which cluster (which group) the objects in the dataset belong to are not known in advance.


