

We continue the series of articles on AI and ML, let us first consider the definition and align what we mean under each term.
What is artificial intelligence (AI), machine learning (ML) and Data Science?
We will consider the question: “What is AI, ML, Data Science, and how do they differ?”
The term Artificial Intelligence is widely used and often understood as a kind of a system (an abstraction) that bears the properties of human intelligence, a system that can think, solve problems (including creative ones); these require the presence of a thought process in the implementation core of the system. Perhaps the most important thing to know is that artificial intelligence as described above does not exist in the present yet. Our brain and consciousness as a whole are too complex and not yet sufficiently studied to digitize them or make a mathematical model that mimics the working of our thought process. However, there are attempts (including quite fruitful ones) to imitate the activity of our brain in solving certain specific problems. A notable direction in AI that falls under this description is ML.
Before moving on to ML, let’s give a more rigorous definition of AI.

Artificial intelligence (AI) is an engineering and mathematical discipline that creates programs, devices and mathematical abstractions that simulate cognitive (intellectual) functions of a person, including, inter alia, data analysis and decision making.
Strong AI / Super-AI – an intelligent algorithm capable of solving a wide range of intellectual tasks, at least on a par with the human mind.
Narrow AI, Weak AI is an intelligent algorithm that imitates the human mind in solving specific highly specialized tasks (playing chess, recognizing faces, communicating in natural language, searching for information, etc.).

Machine learning definition
Machine learning is a class of artificial intelligence methods, designed to draw from data by learning through experience in solving many similar problems, instead of solving the problem directly. These methods are often driven by mathematical statistics, numerical optimization methods, mathematical analysis, probability theory, graph theory, as well as various techniques aimed at working with digital data.
Let’s say we have an algorithm that allows us to trade on an exchange. The algorithm does not know about the existence of the exchange, traders, brokers, etc. It is just a maths model that has been trained to trade on hundreds of thousands of examples.
Likewise, the algorithm that drives a self-driving car has no idea of what a car is, a road, an engine, how all these work together, and so on. The algorithm is trained on a large number of examples of how to solve a particular problem but does not possess the ability to go beyond the framework of a previously formulated problem.
Machine learning algorithms are software implementations of a particular maths model. This model “learns” to solve a particular problem on a large amount of data, to find the patterns in the data to solve a particular task. The main part of this article focuses on ML, the principles behind it and its implementation in projects.

Data science is a broad notion that stands for a field, a profession that focuses on working with data. Data Scientist can stand for a person, working with databases, or someone who designs machine learning algorithms, as well as someone who maintains data managing infrastructure.
“Data science” is as broad of a notion as, for example, “Сomputer science” is.
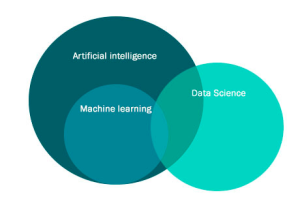
Now, after reviewing the key notions, a question cries out for an answer: “Why do we need ML?”.
We will consider this in the next part (part 3) of our article.


