Data poisoning довгий час обговорювали переважно в контексті adversarial ML, training datasets та контрольованих дослідницьких сценаріїв як теоретичну можливість, реалізація якої вимагатиме значних ресурсів і складних умов. Ще на початку 2025 більшість команд сприймали його як академічну дискусію — важливу для дослідницького середовища, але не завжди пріоритетну для захисту production-систем.
З того часу ситуація стрімко ескалювала. З’явилися реальні та дослідницьки продемонстровані кейси: backdoor через коментарі в GitHub-репозиторіях, прихована інструкція в описі MCP-інструменту, отруєний контент у пошукових результатах, які агент використовує як довірене джерело. Poisoning вийшов за межі training pipeline і почав з’являтися там, де моделі отримують контекст під час роботи.
Отже, для команд, які розробляють або інтегрують GenAI-рішення, це означає, що захист від data poisoning не можна відкладати «на потім».
Що змінилося
Класична модель data poisoning була відносно зрозумілою: у training set додаються маніпульовані або шкідливі приклади, які згодом впливають на поведінку моделі. Це могло призводити до backdoor-поведінки, систематичних помилок класифікації, bias або деградації якості.
Сьогодні модель рідко працює ізольовано. Вона звертається до RAG, корпоративних knowledge bases, векторних баз, API, зовнішніх інструментів, MCP-серверів, synthetic data pipelines і внутрішніх бізнес-систем: тобто поверхня атаки не обмежується training pipeline, ризик виникає в будь-якій точці, де система отримує зовнішній контекст або використовує дані для прийняття рішень.
Poisoned data може потрапити у fine-tuning dataset через open-source repository — непомітно, разом із легітимним кодом або документацією. «Отруєні дані» можуть бути проіндексовані RAG-системою через веб-джерела чи внутрішні файли, які система за замовчуванням вважає довіреними, або приховуватись в описі інструменту, завантаженому агентом як trusted tool, — і спрацьовувати вже після деплою. Нарешті, вони можуть поширюватися через synthetic data: тиражуючи помилки, якщо згенерований контент повторно потрапляє у навчальні вибірки.
Чому Data poisoning критично саме для агентних рішень
Data poisoning стає значно небезпечнішим явищем, коли модель має не лише інформаційний, а й операційний контур.
LLM-агент, який відповідає на запитання в ізольованому середовищі, має обмежений потенціал шкоди. Але агент, який може виконувати SQL-запити, працювати з CRM, запускати workflow, взаємодіяти з файловими сховищами, ticketing-системами або фінансовими сервісами, стає частиною корпоративної операційної інфраструктури. У такому випадку, «отруєна» інструкція або контекст визначає вже не відповідь моделі, а реальну дію, яку вона виконає в системі.
Саме тут проходить межа між «помилкою моделі» і виконнням небажаної/ небезпечної дії системою.
Окремої уваги потребує RAG. Корпоративна база знань не має стати довіреним джерелом автоматично, лише тому, що вона внутрішня. Важливо визначити, хто може додавати, змінювати або видаляти документи, як відбувається перевірка на актуальність, чи зберігається простежуваність даних, чи можуть приховані інструкції потрапити у контекст запиту.
Власне tool layer також має розглядатися як частина поверхні атаки. Якщо агент отримує опис інструменту, endpoint або доступний action як частину контексту, ці елементи потребують перевірки, контролю версій і обмеження прав.
Коментар експерта
Data poisoning є відносно новим поняттям, і тільки в поточному році ми побачили реальні кейси реалізації відповідних ризиків. Механізми захисту активно розробляються. Є цікаві підходи, але наразі немає «золотого стандарту», який повністю унеможливлює цю проблему.
Для корпоративних клієнтів, або в будь-якій іншій ситуації, де витік даних чи небажана дія агента можуть мати серйозний негативний вплив, критичною стає гігієна у розробці й впровадженні агентних рішень. Якщо агент не здатен завдати шкоди (наприклад, не має доступу до інтернету поза заздалегідь затвердженими ендпоінтами, взаємодіє з базами даних виключно через read-only API, тощо), однією з ключових поверхонь атаки з потенціалом операційної шкоди залишається людина, яка може взаємодіяти з цим агентом.
— AI/ML Architect, AM-BITS
Як мінімізувати ризики
Для enterprise-сценаріїв максимальна автономність агента не завжди є перевагою. У багатьох випадках цінність AI-рішення полягає в тому, щоб агент контрольовано прискорював окремі етапи: знаходив інформацію, готував висновок, класифікував запит, формував рекомендацію або пропонував наступний крок, не виконуючи самостійно весь процес – від аналізу до дії. Обмеження автономності агентів є дієвим способом мінімізувати ризики системних помилок LLM-агентів, зокрема, атак на основі data poisoning.
На етапі тестування, окрім «нормального сценарію», необхідно оцінювати «найгірший сценарій», за умови, що retrieved context, tool metadata або user input будуть скомпрометовані. Під час red teaming варто перевіряти не лише prompt injection, а й отруєний контекст у документах, описах інструментів, метаданих, вибірках або синтетичних даних.
Обов’язковим елементом підвищення безпеки є фаховий тренінг для співробітників, які працюють з агентами.
На жаль, жоден із цих підходів не дає повного захисту, а Data poisoning не має універсальної протиотрути. Водночас, вплив можна суттєво зменшити, якщо на етапі архітектури чітко визначити доступ агента, ступінь самостійності і точки людського контролю.
Команда групи компаній AM-BITS взяла участь у Forbes AI DayКоманда групи компаній AM-BITS взяла участь у Forbes AI Day — конференції, присвяченій практичним аспектам впровадження штучного інтелекту в бізнесі та державному секторі.
Під час Forbes AI Day основний фокус був на практичному застосуванні AI. Провідні експерти ділилися досвідом впровадження, показували, як змінюються бізнес-процеси та які підходи дозволяють досягати вимірюваних результатів. Обговорювали інтеграцію AI в традиційні галузі, масштабування рішень, обговорили типові помилки, яких варто уникати.
Подія зібрала сильну С- level аудиторію, тож більшість розмов відбувалась на рівні тих, хто вже прийняв рішення щодо впровадження АІ в бізнесі. Для команди групи компаній AM-BITS це стало ідеальною нагодою звірити підходи до впровадження з тими, хто вже пройшов цей шлях та обговорити очікування бізнесу від АІ. Окремо було корисно отримати практичне розуміння обмежень та складнощів під час впровадження АІ-рішень. Штучний інтелект поступово стає звичною частиною бізнес-процесів у різних галузях та безпосередньо впливає на підхід до прийняття рішень.
У виставковій частині група компаній AM-BITS показала, як будується цілісна система роботи з даними: від збору та управління в Enterprise DataHub, включно з автоматизованим збагаченням через Gathering System, до подальшого використання цих даних у прикладних інструментах. Knowledge Base забезпечує доступ до корпоративних знань, Meeting Notes допомагає структурувати роботу з зустрічами, а CallClarity AI дає можливість аналізувати комунікацію з клієнтами та підвищувати її якість.
Forbes AI Day чітко зафіксував поточний стан ринку, де АІ інтегрується в бізнес-процеси і стає новою нормою, а не просто експериментом.


Термін Machine Learning (машинне навчання) посів важливе місце в сьогоденні — як у трендах новин, так і на ринку праці у сфері автоматизації. Проте ML залишається досить складною темою через свою всеосяжність, новизну та високі темпи розвитку, і залишає безліч питань. Спробуємо розібратись, що таке машинне навчання, дамо основні визначення та поділимось досвідом щодо прикладних завдань, які можна вирішувати за допомогою ML.
Машинне навчання — це набір методів у галузі штучного інтелекту, що їх застосовують для створення моделі, яка навчається на певному наборі даних. В процесі навчання модель обробляє різноманітні масиви вхідних даних і знаходить у них закономірності. Для побудови таких моделей використовуються засоби математичної статистики, чисельні методи, математичний аналіз, методи оптимізації, теорія ймовірності, нейронні мережі та інші техніки роботи з даними у цифровій формі.
Якщо узагальнити, ML — це інструмент, за допомогою якого вирішується певний клас задач, пов’язаних з необхідністю виявити закономірності у складних багатопараметричних завданнях, що не можуть бути вирішені класичними методами через надто велику кількість параметрів чи неочевидність їх пов’язаності.
З чого все починається
Розробка ML‑рішення — це комплексний процес, що вимагає взаємодії різних систем та навичок багатьох фахівців. Наприклад, для збирання та збереження даних відповідний експерт — Data Engineer — розробляє ETL‑процеси та взаємодіє з базами даних. Інший фахівець — Data Analyst — проводить аналіз даних, шукає закономірності та взаємозв’язки, перевіряє статистичні гіпотези. Разом з ними працює ML‑інженер, який розробляє модель рішення, експериментує з різними його архітектурами, шукає оптимальні параметри для отримання найкращого результату.
З 2016 року компанія AM‑BITS успішно реалізує проєкти на основі технологій Big Data, AI та ML, а поштовхом до цього стало партнерство з американським розробником Hortonworks, що є одним з лідерів галузі. З 2019 року AM‑BITS отримав статус «срібного» партнера компанії Сloudera. Наразі AM‑BITS об’єднує досвідчену та сертифіковану команду, що складається з понад 25 експертів з роботи з корпоративними даними. Компанія має досвід у галузі обробки та дослідження даних, зокрема за такими напрямками, як розробка корпоративних платформ даних, впровадження рішень в області обробки та аналізу даних, побудова моделей машинного навчання для технічних і бізнес-задач в різних секторах економіки (фінанси, телеком, медіа).
Під час роботи над ML‑проєктами експерти AM‑BITS надають перевагу платформі Cloudera Data Science Workbench. Завдяки інтегрованій в CDP кластер CDSW платформі різні фахівці мають можливість ефективно реалізовувати проєкти в галузі ML і Data Science (аналіз, обробка та надання даних для аналітичних інструментів) (рис. 1).
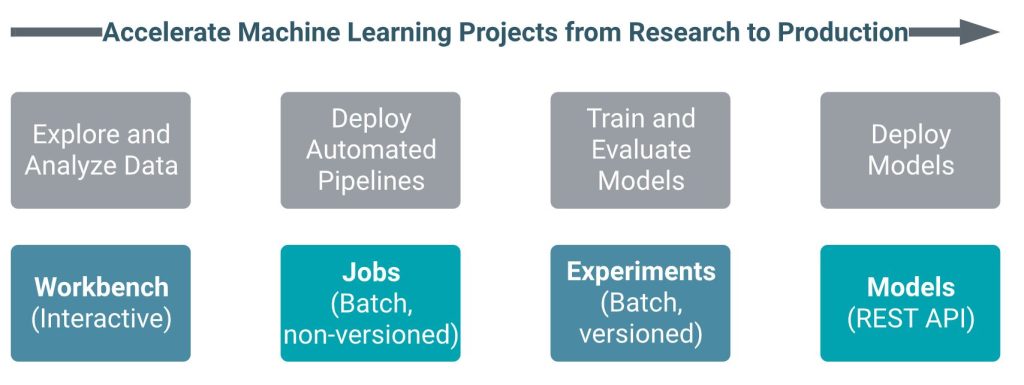
Відповідно до моделі CDSW розробка кожної ML‑моделі ведеться в окремому проєкті, де можуть взаємодіяти члени команди з різними правами доступу залежно від завдань. Таким чином, можна вести розробку проєктів на загальній платформі різним командам (розробникам), при цьому дотримуючись ізольованості один від одного, що дозволяє співробітникам працювати паралельно, використовуючи тільки необхідні ресурси.
Машинне навчання для українських замовників
Практичне застосування ML‑проєктів досить широке. Так, наприклад, інженери AM‑BITS розробили рішення для прогнозування генерації сонячної електроенергії, а також систему для розрахунку очікуваного рівня її споживання. Для побудови точних прогнозів використовувались історичні дані щодо генерації/споживання електроенергії, які було збагачено інформацією щодо прогнозу погоди та інших відкритих даних. Завдяки використанню CDSW вдалося автоматизувати збір необхідних погодних даних, підбір архітектури моделі та гіперпараметрів. Метою обох проєктів було одержання короткострокового прогнозу для планування закупівель на українській енергетичній біржі.
Ось інший приклад. Фахівці компанії AM‑BITS, зокрема, розробили систему ідентифікації особи за обличчям — Face ID (рис. 2). Інженери компанії скористались останніми дослідженнями у сфері розпізнавання облич і на їх основі побудували власне рішення. Модифікувавши та оптимізувавши певні існуючі алгоритми в рамках вирішення поставленої задачі, фахівці отримали модель, яка дозволяє з високою точністю розпізнавати обличчя людей, навіть якщо частина лиця прихована, наприклад, респіраторною маскою. Серед цікавих проєктів можна згадати розробку системи біометричної верифікації клієнтів за голосовими даними.

Задля ефективного порівняння голосових відбитків було побудовано нейромережеву (DNN, Deep Neural Network) модель, що навчається за допомогою бібліотеки PyTorch. Цьому етапу передували отримання голосових відбитків та їх ідентифікація за набором мел-кепстральних коефіцієнтів. Ідентифікація особи за голосом може бути використана для пришвидшення обслуговування в контакт-центрі, миттєво надаючи оператору дані щодо абонента, а також попередню історію комунікацій з метою покращення клієнтського досвіду.
Але можливості машинного навчання не обмежуються прогнозуванням чи ідентифікацією.
Наразі більшість інформації — новини, аналітика, прогнози тощо — створюється та споживається у відеоформаті. Ми створюємо безліч інформаційних повідомлень, фіксуємо щоденні події та ділимось ними з аудиторією, але знайти повторно корисну або просто цікаву інформацію часом надзвичайно складно або навіть неможливо.
З метою полегшення роботи численних аналітиків експерти AM‑BITS розробили багатонодову лінійно-масштабовану платформу для автоматичного аналізу відео за допомогою апаратних графічних процесорів. Для цього були створені моделі машинного навчання з використанням згорткових нейронних мереж (Convolutional Neural Networks) і додаткових моделей оптимізації та відстеження об’єктів. Для швидкої підготовки датасету, необхідного для навчання моделей, було введено додаткову підсистему відеорозмітки. Крім того, розроблено інтерфейс для ведення відеотеки, її перегляду та аналізу, функціонал дозволяє завантажувати відео та обирати моделі аналізу для його обробки (рис. 3).
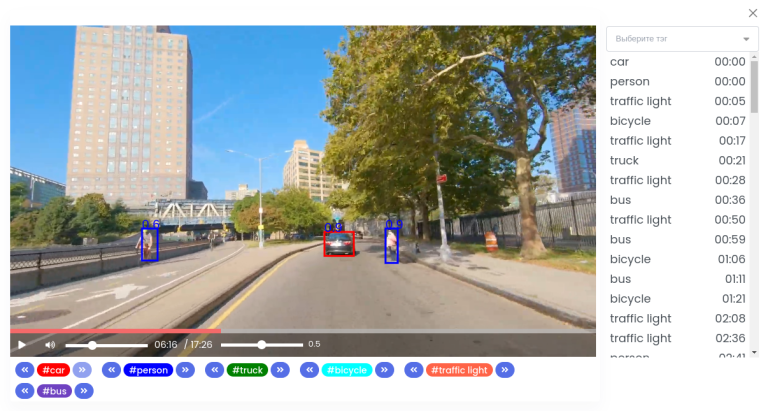
Автоматичне тегування та аналіз відеофайлів дозволяють не лише швидко знайти необхідну інформацію серед переглянутих матеріалів, але й проаналізувати та позначити необхідну інформацію в безперервному відеопотоці, що полегшує роботу експертів, аналітиків, журналістів та інших зацікавлених осіб. Ідентифікацію особи за фото Face ID можна використовувати для швидкого та безпечного підтвердження особи при використанні різних додатків або для запобігання шахрайству та підробленню документів.
Також цей інструмент стане в нагоді у справі виявлення колабораціоністів, бо тегування та аналіз відеоматеріалів можна використовувати не лише для обробки стрічки новин, але і для виявлення на відео військових злочинів з метою подальшого притягнення винних до відповідальності.
Підсумовуючи, варто зазначити, що ML перетворюються на звичний інструмент для вирішення поточних завдань, і команда AM‑BITS допомагає компаніям та організаціям досягати поставлених цілей, зокрема з допомогою цих потужних технологій.
Навіщо потрібен ML та які завдання він вирішує? Машинне навчання (ML). Частина 3ML – це інструмент, за допомогою якого вирішується певний клас завдань.
Перш ніж розглянути основні типи завдань, які вирішують алгоритми машинного навчання, розглянемо наступний приклад, щоб зрозуміти, чому ці завдання не можна вирішити (або так ефективно вирішувати) за допомогою інших відомих методів.

Припустимо, ви хочете мати програму, яка, отримавши на вході фотографію фрукта, могла б сказати: це яблуко чи мандарин? (Замість яблука та мандарину може бути як ракова пухлина на рентгенівському знімку, так і визначення банком шахрайських транзакцій).
1) Найпростіший спосіб вирішити цю проблему – посадити людину з гострим зором, яка б підписувала отримане фото. Очевидно, що такий підхід має свої недоліки:
a. Людина може втомитися, не вийти на роботу
b. Людині потрібно платити заробітну плату, оформити страховку, їй потрібно шукати заміну, коли вона захоче у відпустку
c. Людина (порівняно з комп’ютером) досить повільно виконує поставлене їй завдання
2) Тоді ми вирішуємо замість людини написати програму, яка вирішувала б наше завдання. Ми навіть зберемо провідних експертів у світі з мандарин і яблук і попросимо їх описати програмісту всі можливі відмінності цих фруктів один від одного. В результаті, ми отримаємо програму, яка на основі кольору фрукта, довжини листа та довжини фрукта, каже нам – яблуко це або мандарин. Система працює якийсь час, доки нам не потрапить яблуко з формою листа мандарину або яблуко червоного (майже помаранчевого кольору) як мандарин або яблуко досить круглої форми. Людина відразу побачить, що це яблуко, але наша програма скаже: це мандарин! Тоді ми знову зберемо експертів, обговоримо, чому у нас тут помилка, додамо в програму ще низку правил і так триватиме щоразу, поки ми не досягнемо бажаного результату. Мінуси такого підходу:
а. Висока вартість розробки (оплата експертів, програмістів тощо)
b. Отримана програма буде дуже складною та важкою для підтримки.
c. Великі часові витрати на розробку
d. Неможливість одразу виловити всі можливі залежності у предметній галузі, та описати всі можливі випадки, відмінності.
3) Зрозумівши, що варіанти 1 та 2 нам не підходять, ми шукаємо альтернативні способи вирішення цього завдання та приходимо до алгоритмів машинного навчання. Використовуючи необхідні алгоритми машинного навчання, ми отримуємо програму, яка, навчившись на великій кількості фото яблук та мандарин, вирішує нашу проблему. Із мінусів, потрібна велика кількість розмічених даних (велика кількість фотографій яблук та мандаринів, позначених відповідно).
А тепер уявімо, що у нас не 2 фрукта, а 100, і тут у нас варіант 2 стає зовсім нереалізованим. До того ж це можуть бути не фрукти, а розпізнавання злоякісної пухлини на рентгенівських знімках, детекція шахрайських дій з банківською картою, виявлення спаму у пошті, розпізнавання мови тощо. Є частина завдань, вирішувати які просто нераціонально (а часом неможливо) без участі ML.
Визначившись із питанням навіщо нам потрібен ML, розберемо, для яких завдань він підходить.
Основні завдання, які вирішують алгоритми машинного навчання – це завдання, які важко або неможливо, або нераціонально вирішувати безпосереднім, “явним” (explicit) програмним або аналітичним способом. Серед цих завдань (на кшталт вирішуваних проблем) можна виділити наступні 4:
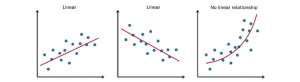
Регресія — це завдання прогнозування значення безперервної числової величини для певного об’єкта на основі його характеристик. Наприклад, прогноз цін на ринку нерухомості, прогноз температури, кількість грошей, витрачених у магазині клієнто тощо.
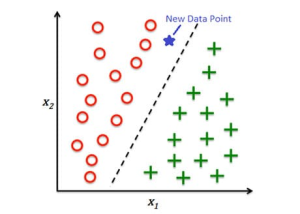
Класифікація — це завдання передбачити категоріальний атрибут об’єкта. Наприклад, категоризація вхідних листів на спам і не спам, завдання кредитного скорингу, класифікація зображень тощо.
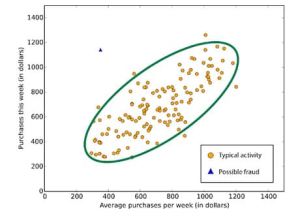
Виявлення аномалій — це завдання ідентифікації елементів, подій або спостережень, які не відповідають очікуваному шаблону або іншим елементам у наборі даних. Прикладами такого завдання може бути: детекція шахрайства, детекція відмови працездатності системи, пошук помилок у тексті тощо.
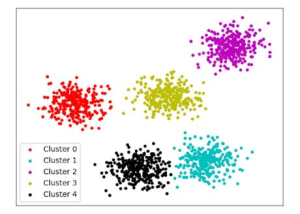
Кластеризація — це завдання групування подібних об’єктів у кластери. На відміну від задачі класифікації, кількість кластерів і до якого кластера (до якої групи) належать об’єкти в наборі даних заздалегідь невідомі.
Що таке AI, ML та Data Science? Машинне Навчання (ML). Частина 2Отже, ми продовжуємо цикл статей про AI та ML. Для початку розглянемо ключові терміни.
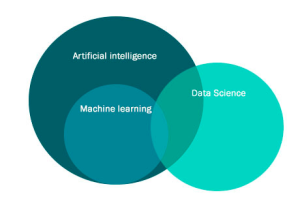
Що таке Штучний інтелект (AI), ML та Data Science?
Давайте спробуємо відповісти на питання: що таке Штучний інтелект, ML, Data Science та яка різниця між ними?
Найчастіше під терміном Штучний інтелект ми маємо на увазі, що це якась система (абстракція), що має властивості інтелекту людини та яка може мислити, вирішувати завдання (у тому числі творчі), для виконання яких використовується розумовий процес. Мабуть, найважливіше, що треба знати – штучного інтелекту, описаного вище, на даний момент не існує. Занадто складні наші мізки і свідомість, загалом, для того, щоб їх оцифрувати чи зробити математичну модель, яка копіює роботу нашої свідомості. Проте, є спроби (зокрема досить вдалі) імітації діяльності нашого мозку для вирішення тих чи інших завдань. Одним із напрямків Штучного інтелекту, що підпадає під таке формулювання, є Machine Learning (ML).
Перш ніж перейти до ML, дамо строгіше визначення Штучного інтелекту.

Штучний інтелект, (Artificial Intelligence, AI) – інженерно-математична дисципліна, що займається створенням програм та пристроїв, що імітують когнітивні (інтелектуальні) функції людини, що включають, у тому числі, аналіз даних та прийняття рішень.
Сильний ШІ / Людиноподібний ШІ (Strong AI, Super‑AI) — інтелектуальний алгоритм, здатний вирішувати широкий спектр інтелектуальних завдань, як мінімум, в рівень з людським розумом.
Слабкий ШІ / Спеціальний ШІ (Narrow AI, Weak AI) — інтелектуальний алгоритм, що імітує людський розум для вирішення конкретних вузькоспеціалізованих завдань (гра в шахи, розпізнавання осіб, спілкування людською мовою, пошук інформації тощо).

Машинне навчання – клас методів штучного інтелекту, характерною рисою яких є не пряме розв’язання задачі, а навчання за рахунок досвіду розв’язків безлічі подібних завдань. Для побудови таких методів використовуються засоби математичної статистики, чисельних методів оптимізації, математичного аналізу, теорії ймовірностей, теорії графів, а також різні техніки роботи з даними в цифровій формі.
Припустимо, ми маємо алгоритм, за допомогою якого можна торгувати на біржі. Він не знає про існування біржі, трейдерів, брокерів тощо, — це просто математична модель, яка навчена торгувати на сотнях тисяч прикладів. Аналогічно, алгоритм, який керує безпілотним автомобілем, не має уявлення про те, що таке автомобіль, дорога, двигун, як він працює, і так далі. Алгоритм навчений на великій кількості прикладів як вирішувати ту чи іншу задачу, але не має здатності виходити за рамки сформульованої заздалегідь задачі.
Алгоритми машинного навчання – це програмна реалізація тієї чи іншої математичної моделі. Ця модель, на підставі великої кількості даних, “навчається” вирішувати те чи інше завдання, знаходячи потрібні закономірності в даних. Саме машинному навчанню та принципам роботи, реалізації його у проектах і буде присвячена основна частина серії статей.

Data science – це узагальнена назва сфери діяльності, професії, в якій основний акцент робиться на роботі з даними. Дата Саєнтистом може бути людина, яка працює з базами даних, або яка розробляє алгоритми машинного навчання, так і спеціаліст, який обслуговує інфраструктуру, призначену для роботи з даними.
Data science – це таке ж узагальнене визначення, як і Сomputer science.
Тепер, розібравшись у термінах, залишається питання: “А навіщо потрібен ML?”
Продовження та відповідь на це питання читайте у наступній статті (частина 3) …
AM-BITS за підтримки Cloudera – Технологічний партнер конференції UAFIN.TECH 2021Запрошуємо наших друзів та знайомих на спільну презентацію представників AM-BITS та Cloudera під час конференції UAFIN.TECH 2021, яка відбудеться 8го грудня в КВЦ «Парковий». UAFIN.TECH 2021 – це унікальна концентрація провідних експертів, інвесторів, банкірів та топ-менеджерів найбільших компаній. Спільна доповідь відбудеться в потоці «Майбутнє технологій».
Вперше в Україні, наживо, представники компанії Cloudera розповідатимуть про новітні тенденції та, разом з CEO AM-BITS, Євгеном Манжуляновим, поділяться досвідом та успішними кейсами у фінансовій сфері.
Нагадаємо, що AM-BITS – єдиний партнер Cloudera в Україні зі статусом Cloudera Silver Partner, що підтверджує наявність експертної команди та відповідного досвіду.
До зустрічі!
———–
Cloudera – американська компанія, розробник найбільш повного та всеохоплюючого комплексу програмних продуктів для роботи з великими даними. Комплексна платформа надає інструменти для роботи з даними для кожного етапу життєвого циклу даних, та забезпечує всі вимоги щодо роботи з чутливими даними, включаючи безпеку даних, керування даними, машинне навчання, аналітику, тощо. Всі інструменти оптимізовані для хмарної та гібридної інфраструктури. 9 з 10 найбільших банків світу працюють з Cloudera.
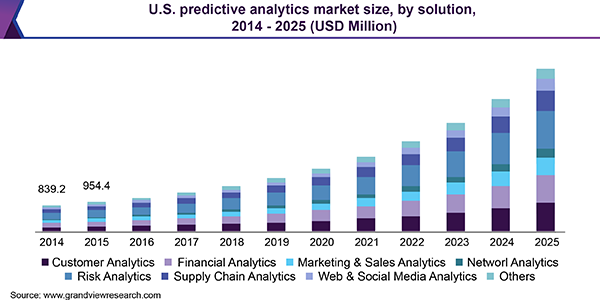
Предиктивна аналітика: ключові переваги та перспективи ринкуМайбутнє більшості комерційних і некомерційних галузей нерозривно пов’язане з інноваціями. Всесвітньо відомі корпорації інвестують мільярди доларів в технології Big Data, штучний інтелект і машинне навчання. Таким чином, сектор предиктивної аналітики (ПА) є каталізатором для отримання прибутку за допомогою інновацій.
В 2019 році ринок ПА досяг обсягу в 7,32 мільярди доларів, відповідно до дослідження AMR. До 2027 року ця цифра збільшиться до $35,45 мільярда – аналітики очікують ріст сектора на 484%. Що ж таке «предиктивна аналітика» і чому вона настільки важлива для сучасних компаній?
Предиктивна аналітика: поняття і основні принципи
Якщо звернутися до терміну «аналітика» в цілому, то сам процес розуміється як системний чисельний аналіз даних і статистик з метою виявлення значимих шаблонів та їх використання для прийняття ефективних рішень. Предиктивна аналітика посідає другу сходинку в ієрархії аналітичного процесу.
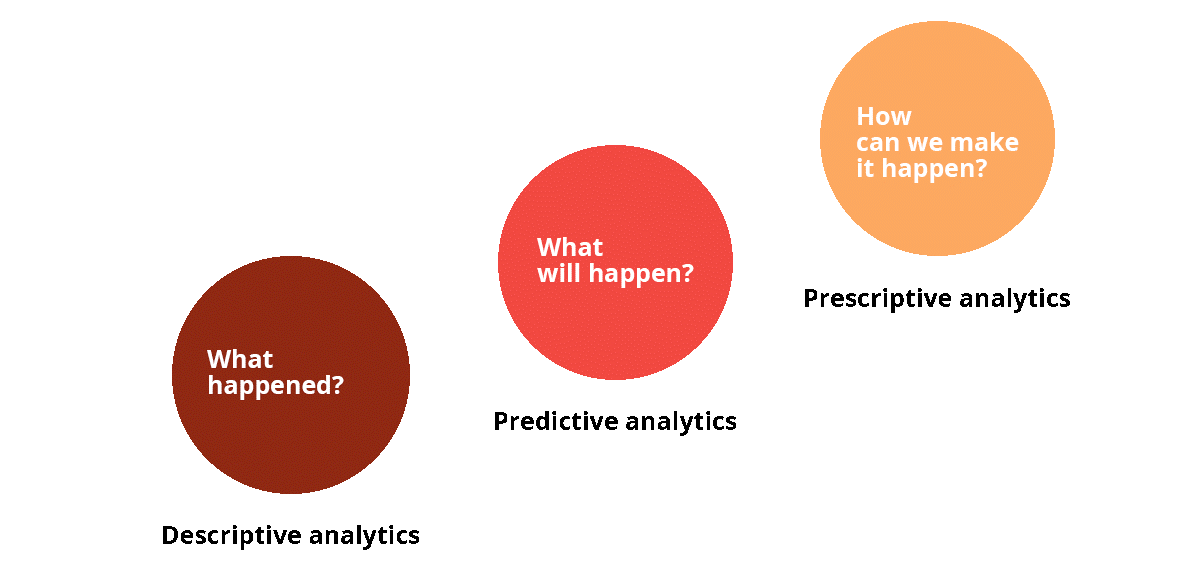
Механізми ПА відповідають за прогнозування того, що відбудеться в майбутньому в конкретній галузі. Предиктивна аналітика визначається як окремий клас методів аналізу даних, пов’язаних із визначенням моделей поведінки суб’єктів або об’єктів у майбутньому. Перші кроки в цьому секторі були зроблені ще в 1940-х роках, проте сучасні технології, до складу яких входять штучний інтелект, машинне навчання та Big Data, відкрили нові горизонти для ринку ПА.
Процес предиктивної аналітики базується на чотирьох ключових компонентах. Перші дві стадії передують ПА, проте побудова аналітичного процесу без них не можлива.
- Постановка завдання:
Саме постановка завдання разом з формулюванням гіпотези, що оцінює можливість передбачення бажаного на підставі певних даних, багато в чому визначає наступні кроки.
- Збір даних:
Дані – основа будь-якого статистичного аналізу, до технік якого відноситься і машинне навчання. При зборі даних важливими є два фактори: їх обсяг (глибина датасету) та їх якість. Технології Big Data є потужним допоміжним інструментом при зборі необхідного обсягу даних.
- Розвідувальний аналіз даних:
Отримані обсяги сирих даних самі по собі недостатні для прогнозування. Виявлення закономірностей в сучасних обсягах даних вимагає адекватного підходу. Згідно IDC, щорічне зростання використовуваних обсягів даних становить 20,4% в той час як загальний обсяг використовуваних даних, на думку аналітиків, досягне 8,9 зеттабайт до 2024 року. Технології штучного інтелекту допомагають не загубитися серед обсягів сирих даних, виявляючи приховані співвідношення.
- Предиктивне моделювання:
Виявлення інсайтів в даних – наступний, завершальний етап. Цей етап полягає у побудові математичної предиктивної моделі задля вирішення поставленого завдання. Сучасним трендом є використання машинного навчання на цій стадії.
Головні переваги предиктивної аналітики
Чому сучасним компаніям необхідно впроваджувати механізми ПА для збільшення прибутків? Коли ви розробляєте новий продукт або послугу, тисячі або навіть мільйони доларів спрямовуються на аналіз ринку. При цьому, як власник бізнесу, ви розраховуєте отримати точну відповідь – чи буде продукт або послуга успішні.
Предиктивна аналітика надає власникам компаній багато переваг:
● Підвищення точності сегментації ринку. ПА методи допомагають менеджерам з продажу побудувати більш точний образ цільового покупця.
● Збільшення конверсії. На основі інформації про попередні продажі, можна ефективніше знаходити нових потенційних покупців.
● Збільшення ефективності прогнозування продажів. Спираючись на точні прогнози продажів, компанії зможуть ефективніше планувати прибуток протягом фінансового року.
● Кластеризація клієнтів. ПА механізми дозволяють власникам бізнесів розділити велику кількість клієнтів на певні групи, щоб запропонувати їм максимально релевантні товари і послуги.
● Виявлення прихованого потенціалу. Предиктивна аналітика допомагає компаніям створити родючий ґрунт для майбутнього розвитку.
Методи предиктивної аналітики можна застосовувати у різних галузях, як в комерційному так і в державному секторі.
- Охорона здоров’я. Автоматизоване предиктивне моделювання допомагає запобігти хронічні хвороби і рецидиви травм, ґрунтуючись на зібраних історіях хвороби і внесених в них нових даних.
- Безпека дорожнього руху і страхування. Предиктивна аналітика дозволяє персоналізувати автомобілі під конкретні категорії водіїв, активуючи необхідні налаштування і додатки, а також використовувати набір обмежень з метою запобігання ДТП.
- Туристичний сектор. ПА механізми можуть передбачити збільшення популярності конкретного напрямку.
ПА методи є ефективними для вирішення завдань фінансового сектору, сільського господарства, в побудові прогнозів погоди та в інших галузях. На сучасному етапі розвитку предиктивна аналітика найбільш активно застосовується для управління ризиками, для фінансового аналізу та прогнозування споживацької аудиторії.
5 успішних кейсів використання предиктивної аналітики в бізнесі: короткий огляд
Розглянемо кілька реалізованих кейсів, в яких використання предиктивної аналітики допомогло вивести бізнес на новий рівень.
1. Використання алгоритмів машинного навчання для прогнозування результатів матчів NBA.
Завдання: клієнту була потрібна модель на основі машинного навчання для прогнозування шансів кожної команди NBA на перемогу в наступній грі.
Стратегія: модель побудована на рекурентній нейронній мережі, об’єднаної з аналізом великих обсягів інформації про результати минулих ігор NBA.
Рішення: модель на основі РНН мережі демонструє високу точність передбачення. Розробники планують протестувати модель на основі темпоральної згорткової мережі, що забезпечує розпізнавання зображень і відео для поліпшення результатів прогнозу.
Результати: на поточному етапі вдалося отримати 80% точності прогнозів.
2. Застосування сервісів на основі технологій штучного інтелекту для ефективного управління активами.
Завдання: компанії Catana Capital потрібен був високоефективний сервіс для точного прогнозування трейдингових операцій та управління активами.
Стратегія: сервіс спирається на технологію Big Data, штучний інтелект і методи предиктивної аналітики. Вивчаються тисячі новин, фінансових статей, дописів в соцмережах, статей у корпоративних блогах та інша інформація задля детальнішого аналізу ринку.
Рішення: сервіс використовує котировки понад 45 тисяч акцій, щоб отримати найбільш точні прогнози подальшого руху ціни.
Результати: в даний час, сервіс Catana Capital користується високим попитом серед трейдерів з різних країн.
3. Впровадження біометричної верифікації на основі голосових даних
Завдання: необхідно було створити ефективну і безпечну систему автентифікації для кол-центрів, зручну для користувачів і стійку до кібератак.
Стратегія: розробити надійну систему автентифікації на основі голосових даних задля подальшого впровадження у кол-центрах. Вона включає базу даних голосових зразків для ідентифікації користувачів.
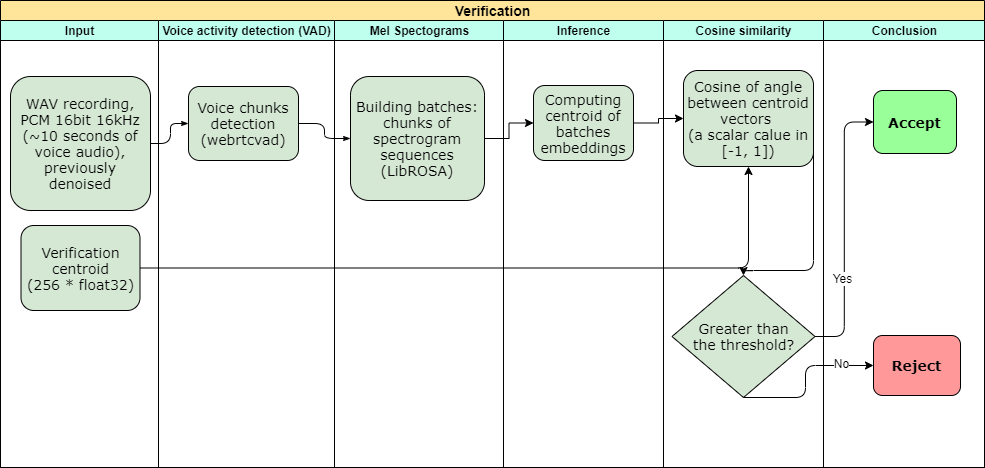
Рішення: в якості основи обрана нейронна мережа, що забезпечує відповідність голосу конкретного користувача голосовому зразку з бази даних.
Результати: власники бізнесу отримали систему автентифікації на основі голосових даних. Система характеризується високим ступенем безпеки, скорочує час верифікації і підвищує ефективність процесу автентифікації. Детальніше…
4. Оптимізація руху грошових коштів в мережі банкоматів
Завдання: зазвичай, при керуванні мережею банкоматів, оператори стикалися з низкою суттєвих труднощів, пов’язаних з зайвими витратами і неточним моніторингом. Був потрібен розрахунок оптимальної кількості грошових коштів для інкасації.
Стратегія: за допомогою методів предиктивної аналітики прогнозується добова кількість видачі грошових коштів і визначаються оптимальні показники cash flow.
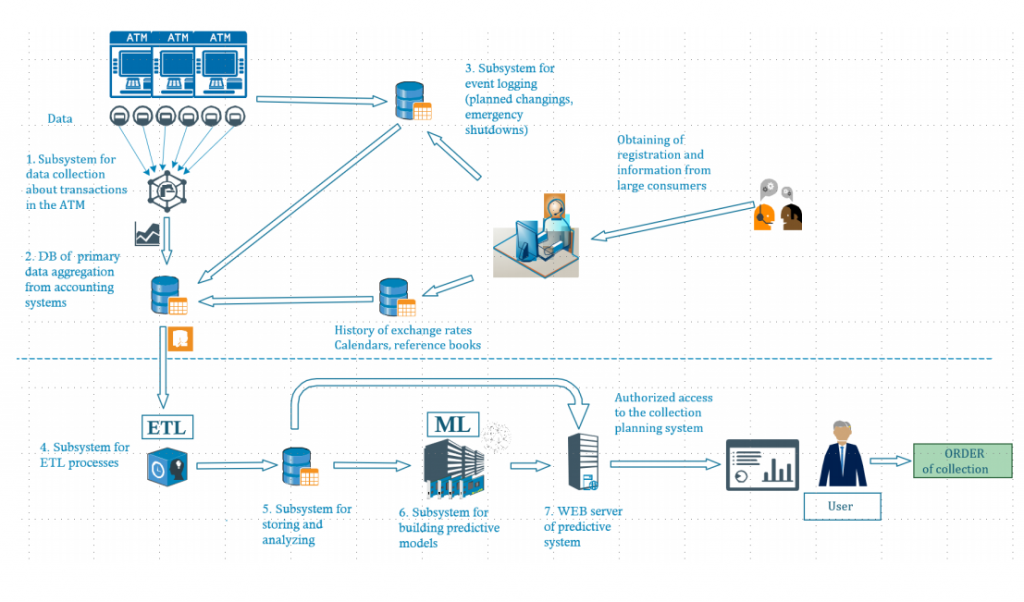
Рішення: спираючись на дані банкоматів, добова кількість видачі грошових коштів прогнозується з максимальною похибкою в 0,01-3,5%.
Результати: ефективність використання готівкових коштів збільшена на 15-40%, а час простою банкоматів зменшено до 0,2%. Детальніше…
5. Точний прогноз показників споживання електроенергії
Завдання: енергетичній компанії була потрібна ефективна модель розрахунку споживання електроенергії, заснована на машинному навчанні. Крім того, завдання передбачало створення системи прогнозування з метою планування закупівельних обсягів на енергетичній біржі.
Стратегія: рекурентна нейронна мережа використана для побудови системи прогнозування з максимально точними показниками.
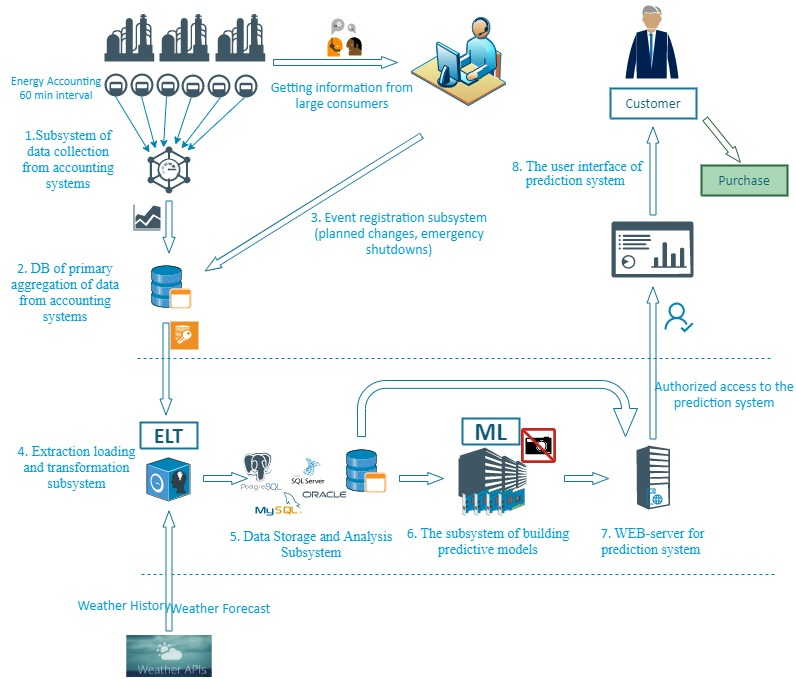
Рішення: з відкритого доступу були взяті дані погодинного споживання електроенергії в Нью-Йорку і температурні коливання, на основі яких побудована модель прогнозування споживання за 2-денний період.
Результат: отримана модель прогнозування з елементами машинного навчання надає замовнику дані з показниками точності 96,4-99,5%. Детальніше…
Висновок:
Методи ПА відкривають нові горизонти для бізнесу, тому багато компаній залучають фахівців у галузі предиктивної аналітики, штучного інтелекту та інших інноваційних технологій для реалізації внутрішніх завдань. Як правило, економічно виправданим рішенням є залучення спеціалізованої компанії, що має релевантний досвід та достатню кількість фахівців, які готові розробити та впровадити складне комплексне рішення.
Компанія AM-BITS є системним інтегратором BigData рішень, у нашому портфелі є не лише послуги, пов’язані з предиктивною аналітикою, а й з побудови Enterprise DataHub, Streaming processing, Active Archive та інші. Ми будемо раді обговорити Ваші задачі по роботі з корпоративними даними та запропонувати найбільш релевантне рішення.
Машинне навчання (ML).Частина 1
Вступ
Термін машинне навчання зараз можна почути буквально на кожному кроці. Поняття Machine Learning (ML) міцно зайняло своє місце як у трендах новин, так і на ринку праці у сфері автоматизації. Звідусіль долинають історії успішного впровадження “Штучного Інтелекту” в процеси компаній, а професія data scientist отримує звання “The Sexiest Job of the 21st Century”.
Проте, незважаючи на величезну популярність, ML залишається досить складною для розуміння темою через свою всеосяжність, новизну та високі темпи розвитку (що породжує купу міфів), і залишає безліч питань без відповіді для людей, які намагаються розібратися в цій темі.
Основна мета цієї серії статей – доступною мовою розповісти про те, що таке ML, де і як воно застосовується, які завдання вирішує, та розвіяти кілька міфів, пов’язаних із цим поняттям, але найголовніше – познайомити Вас з базовими поняттями та концепціями, необхідними для реалізації власного ML проекту. У цій статті ми розглянемо, що таке Машинне навчання, дамо основні визначення Machine Learning, дізнаємось з яких етапів складається реалізація ML проекту, та які завдання можна вирішувати за допомогою Machine Learning.
Ми розпочнемо з базових понять і поступово будемо заглиблюватися в сутність теми, але спочатку – розглянемо простий приклад.

Припустимо, що ми маємо агенцію, яка перепродає автомобілі, та існує потреба в інструменті, який дозволив би на основі доступної інформації про автомобіль передбачити його вартість на вторинному ринку (за скільки його можна буде перепродати). Компанії потрібно аналізувати велику кількість оголошень з різних сайтів оголошень, та першою реагувати на вигідні пропозиції (менше ніж за секунду після того, як вони з’являться). Але щодня з’являється безліч оголошень на різних ресурсах, і відстежити їх вручну практично неможливо.
Для задоволення цієї потреби ми плануємо розробити програмного помічника, який за нас перебирав би оголошення і знаходив релевантні. Він би передбачав ціни на авто на вторинному ринку, і, якщо його прогнозована ціна вища, ніж та, за яку ми можемо це авто купити, оголошення відправляється експерту на розгляд.(Читати детальніше про кейс).
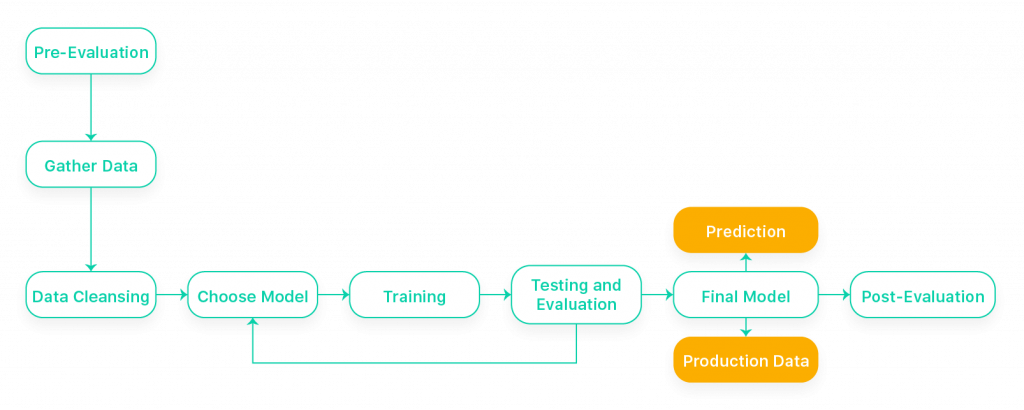
Тоді для вирішення завдання нам знадобиться:
1) Чітко сформулювати завдання (побудувати алгоритм прогнозування ціни автомобіля на вторинному ринку на основі його властивостей).
2) Зібрати дані про автомобілі, що зберігаються на сайтах оголошеннь. На основі цих даних ми навчатимемо алгоритм і будуватимемо прогнози.
3) Зробити попередню обробку даних (привести дані у табличний вигляд, очистити, збагатити дані, обробити пропуски).
4) Побудувати предиктивну модель.
5) Розробити програмну інфраструктуру під цю задачу та інтегрувати в неї наш алгоритм із пункту 4.
Реалізувавши ці кроки, ми отримаємо програму, яка сама збирає оголошення про продаж автомобілів з сайтів оголошень, аналізує їх та передає експерту лише ті, що з великою ймовірністю є фінансово вигідними.
Як бачимо, ML – це не чарівна паличка, яка сама по собі вирішує будь-яке завдання, а комплексний інструмент, який потрібно правильно інтегрувати, а ефективному результату завжди передує процес дослідження та розробки власне ML алгоритмів.
Наш приклад демонструє, як можна використовувати Машинне навчання (ML) для автоматизації бізнес-процесів, а також, що важливіше, ознайомлює нас з основними пунктами (1-5) розробки ML проекту. Слід враховувати, що реалізація ML проекту – це комплексне і досить складне завдання. Щоб отримати більше уявлення про те, що таке Машинне Навчання, – пропоную ознайомитись з наступною статтею “Що таке AI, ML та Data Science?“
А поки що, можете ознайомитися з ML кейсами, реалізованими нашою командою: https://am-bits.com/solutions/analytics-projects